Time to delve into the actual estimates given by summary()!
Under Estimate, we get the mean of the posterior distribution of each parameter.
Under Est.Error, we get the standard deviation.
Under l-95% CI, we get the 2.5th quantile of the posterior (the lower bound of the 95% Credible Interval).
Under h-95% CI, we get the 97.5th quantile of the posterior (the upper bound of the 95% Credible Interval).
summary(acc_fit)
Family: bernoulli
Links: mu = logit
Formula: sentence_accepted ~ cond + sent + condsent
Data: acc (Number of observations: 1476)
Draws: 4 chains, each with iter = 2000; warmup = 1000; thin = 1;
total post-warmup draws = 4000
Population-Level Effects:
Estimate Est.Error l-95% CI u-95% CI Rhat Bulk_ESS Tail_ESS
Intercept 0.32 0.06 0.20 0.43 1.00 4147 2917
cond -0.18 0.11 -0.41 0.04 1.00 4133 2921
sent 1.84 0.12 1.62 2.08 1.00 4506 3221
condsent 0.22 0.12 -0.01 0.45 1.00 4438 3089
Draws were sampled using sample(hmc). For each parameter, Bulk_ESS
and Tail_ESS are effective sample size measures, and Rhat is the potential
scale reduction factor on split chains (at convergence, Rhat = 1).
We’ll go through these estimates now one by one and talk about how they can be understood. The parameter interpretations laid out here deviate in some important ways from the frequentist way of thinking. Before you read on, I encourage you to think about how you would interpret these numbers if they came out of, say, glm(), and compare that to the interpretations given here.
Interpreting coefficient estimates
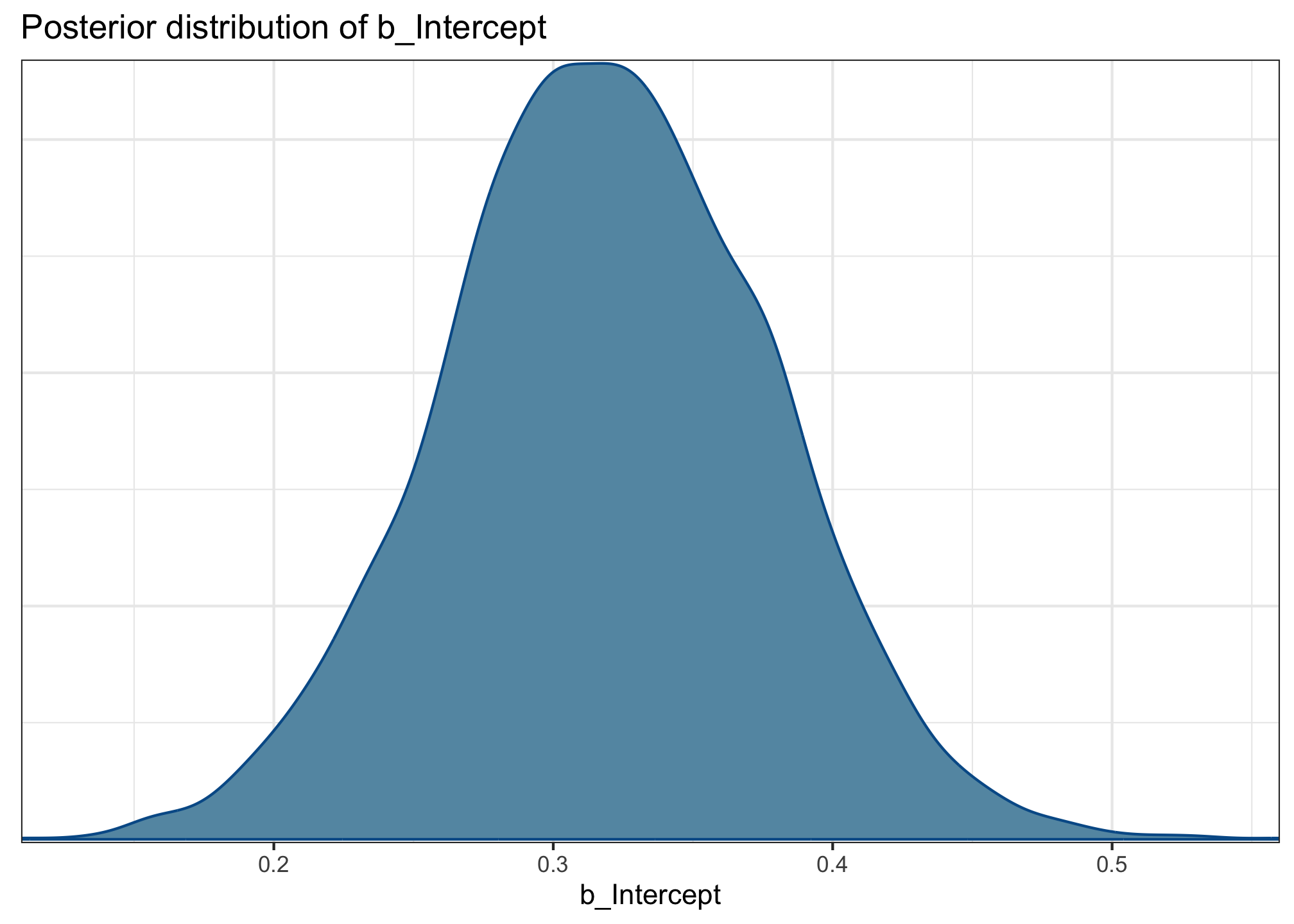
b_Intercept (aka \(\alpha\))
mcmc_dens(acc_fit, pars ='b_Intercept') +labs(title ='Posterior distribution of b_Intercept')
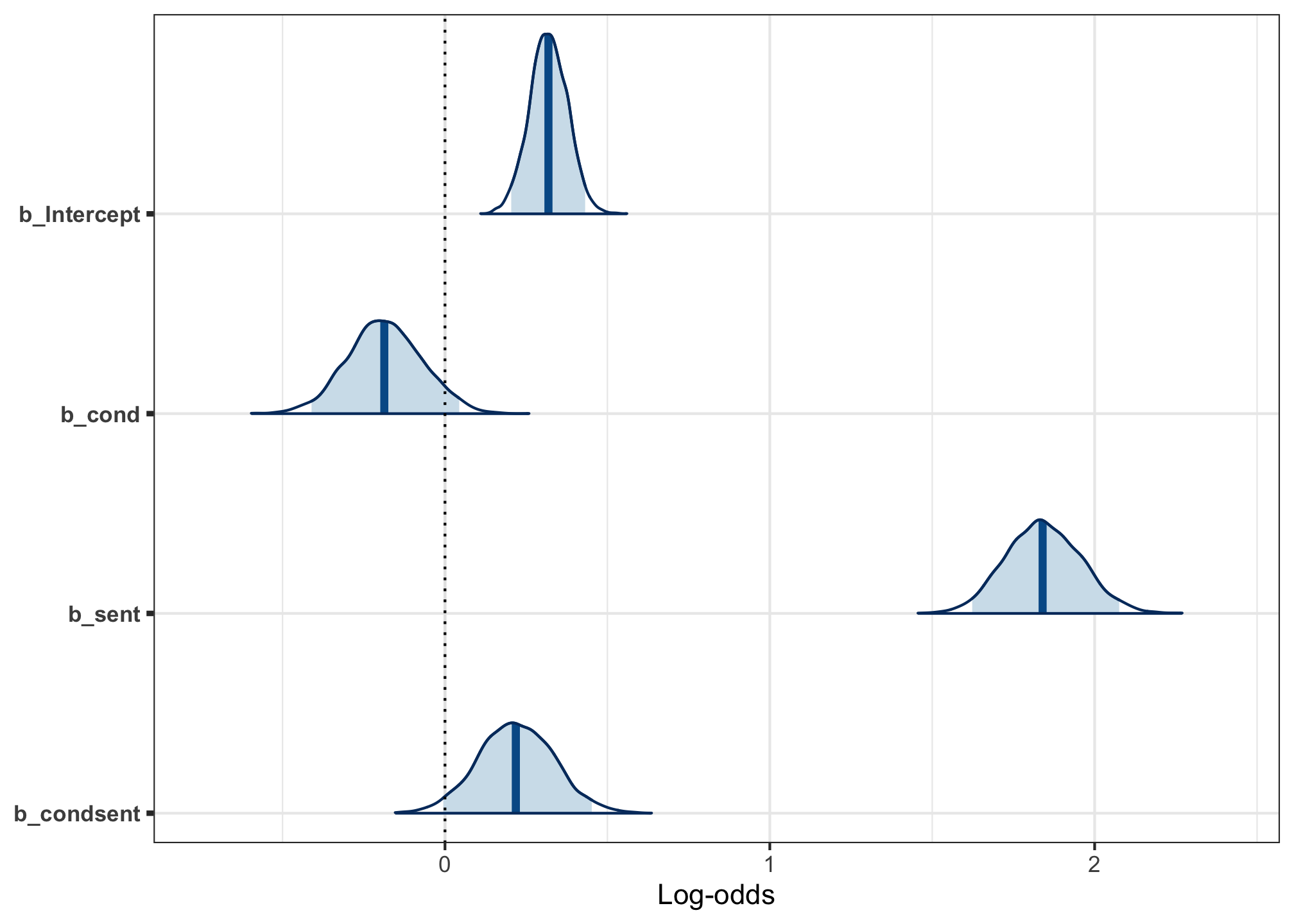
The estimated mean log-odds of accepting a sentence when all predictors = 0 is 0.32 log-odds (95% CrI: [0.20, 0.43]). This means that the posterior mean is 0.32 log-odds, and 95% of the posterior lies between 0.20 log-odds and 0.43 log-odds.
Because the posterior distribution is a distribution of belief over plausible parameter values, this means that the model thinks there’s a 95% probability that the intercept of this model is between 0.20 log-odds and 0.43 log-odds.
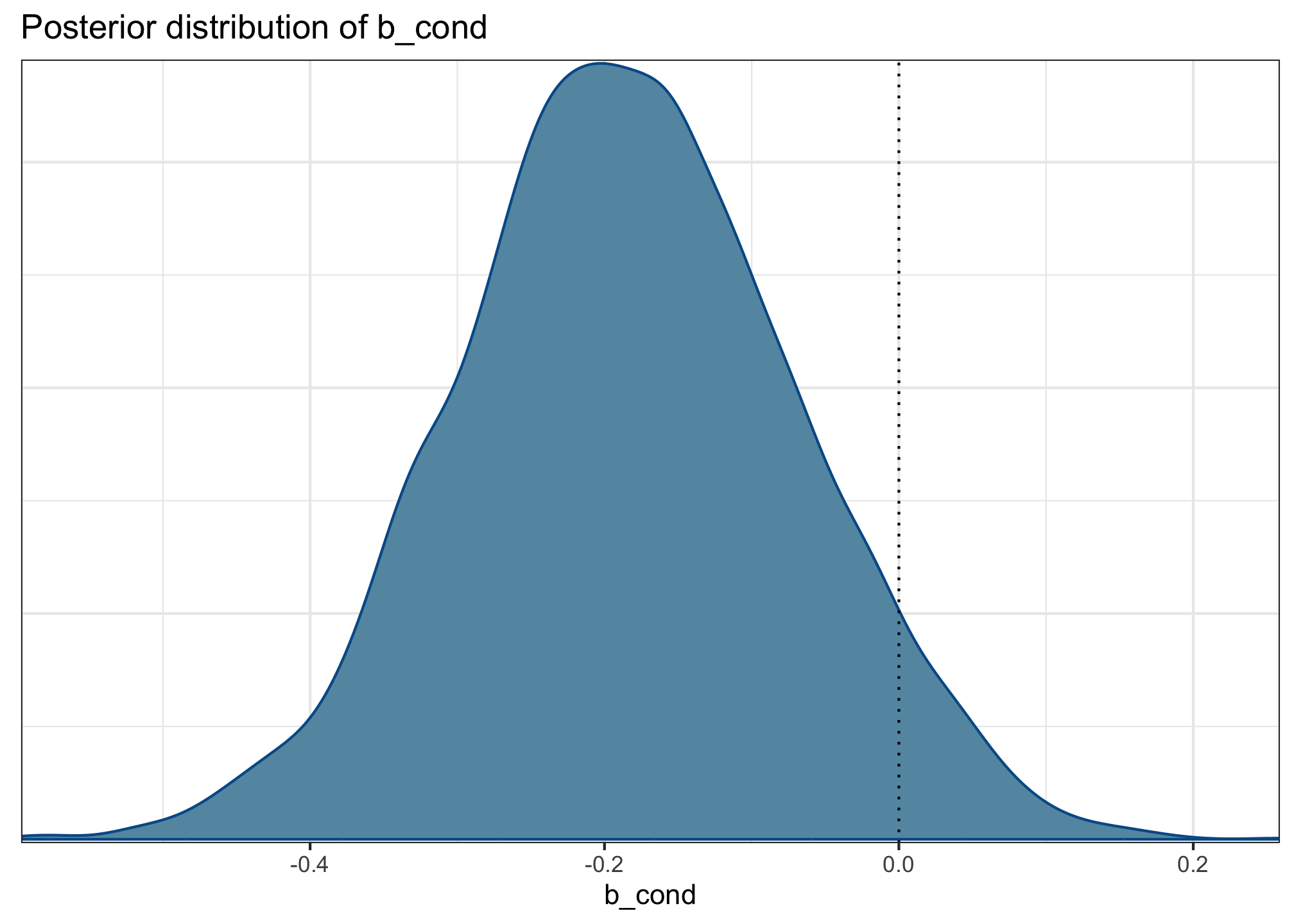
b_cond (aka \(\beta_1\))
mcmc_dens(acc_fit, pars ='b_cond') +labs(title ='Posterior distribution of b_cond') +geom_vline(xintercept =0, linetype ='dotted')
The mean effect of condition—i.e., the difference between production (+0.5) and comprehension (–0.5)—is –0.18 log-odds (95% CrI: [–0.41, 0.04]).
Because the mean effect is negative, the model estimates that participants are, on average, more likely to accept sentences in the comprehension condition than the production condition. But, because the 95% CrI spans both positive and negative values, the model is not entirely certain about the direction of the effect. It believes that a small positive effect may also be consistent with this data.
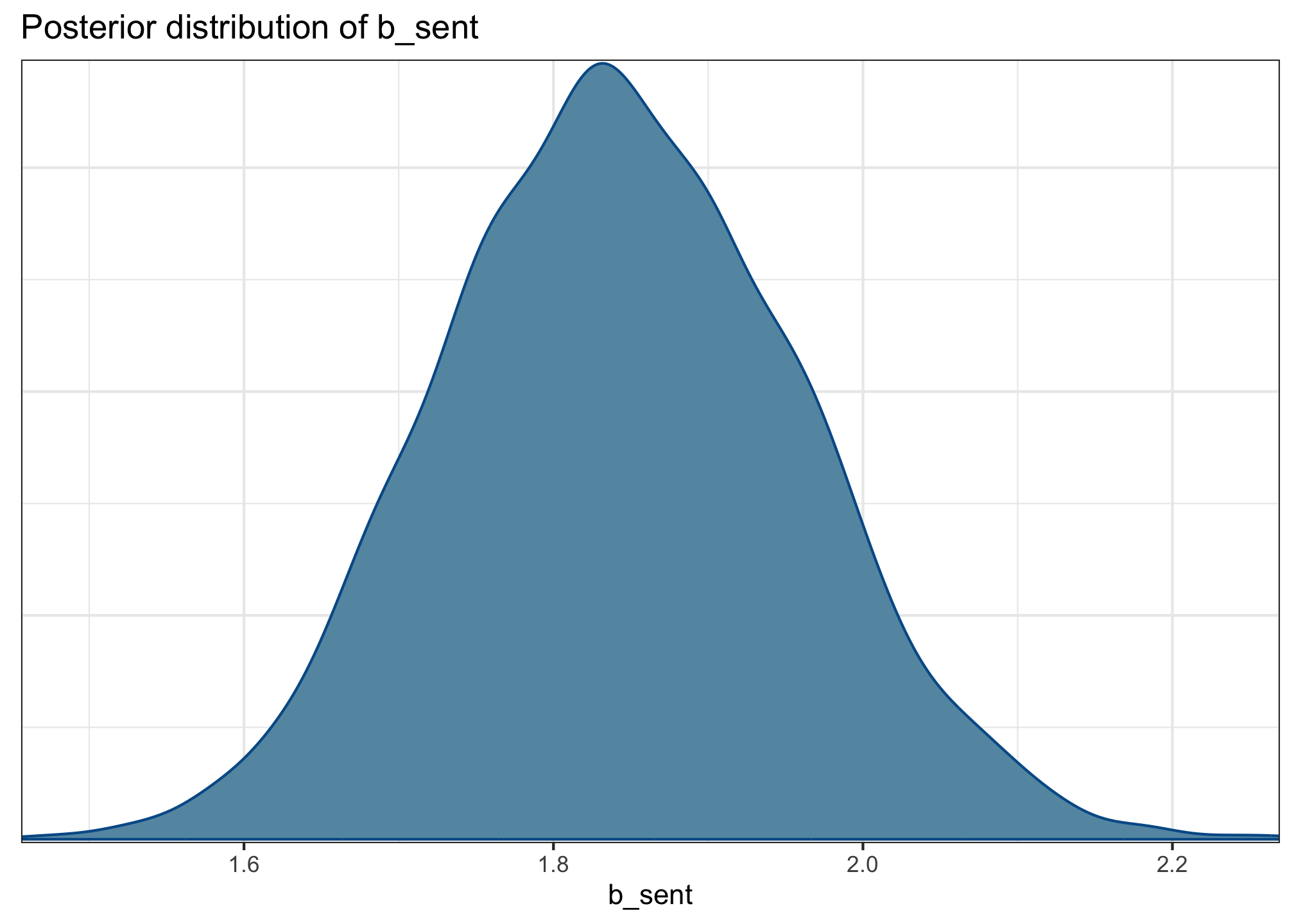
b_sent (aka \(\beta_2\))
mcmc_dens(acc_fit, pars ='b_sent') +labs(title ='Posterior distribution of b_sent')
The mean effect of sentence type—i.e., the difference between word order (+0.5) and case marking (–0.5)—is 1.84 log-odds (95% CrI: [1.62, 2.08]).
Because the entire 95% CrI is positive, the model is quite certain that this is a positive effect: participants are more likely to accept word order sentences than case-marking ones. This is also quite a large effect, compared to the others in the model.
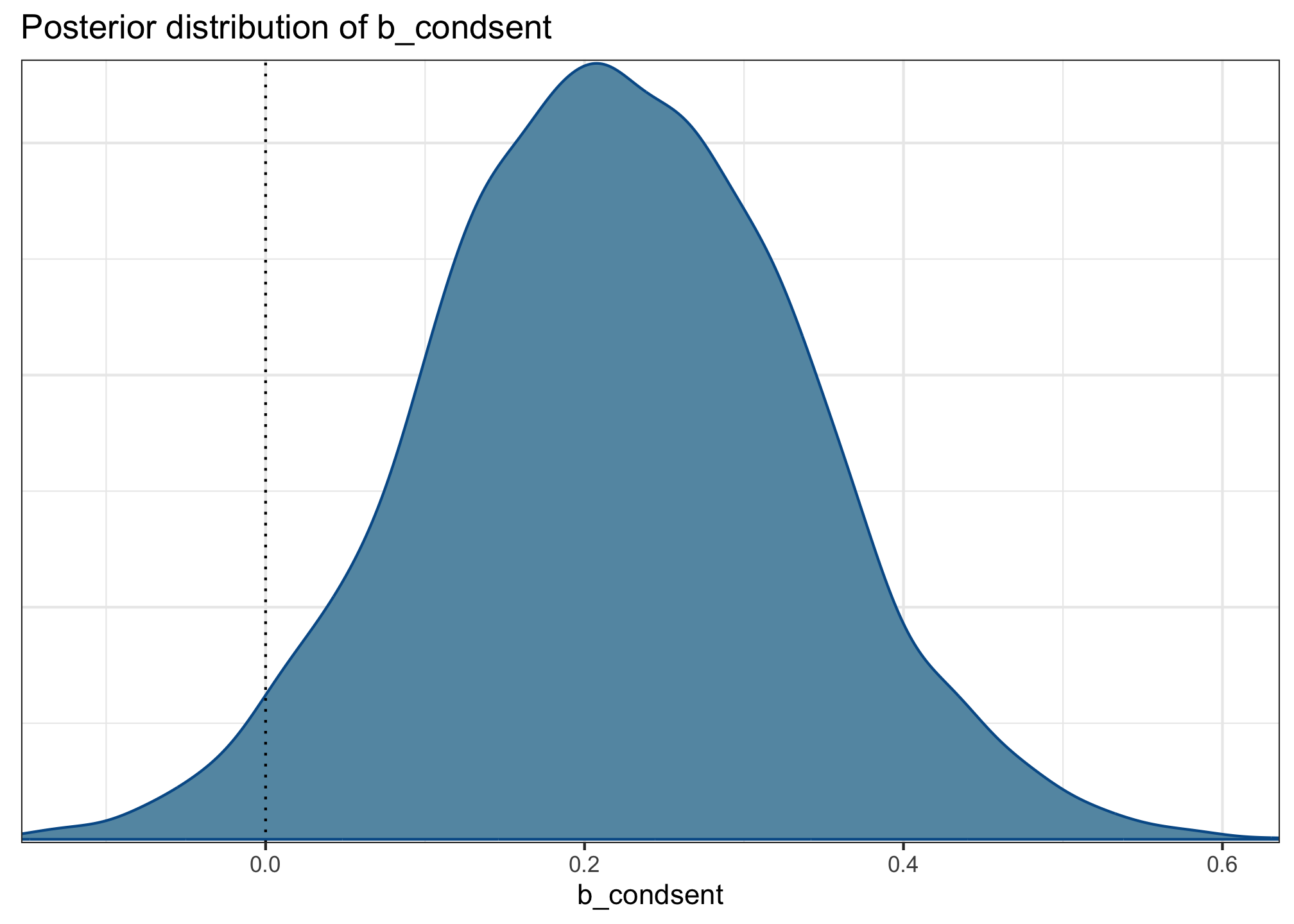
b_condsent (aka \(\beta_3\))
mcmc_dens(acc_fit, pars ='b_condsent') +labs(title ='Posterior distribution of b_condsent') +geom_vline(xintercept =0, linetype ='dotted')
The interaction between condition and sentence type is estimated at 0.22 log-odds (95% CrI: [–0.01, 0.45]).
Again, because the 95% CrI contains both positive and negative values, the model is not entirely certain about the direction of the interaction. It thinks that it likely is positive—which we can interpret as a larger difference between sentence types in the production condition than in the comprehension condition—but it also is leaving open the possibility that the interaction may be small and negative.
Bayesian vs. frequentist interpretations
Consider the interpretations of b_cond and b_condsent. Both of their 95% Credible Intervals span both positive and negative values—in other words, the intervals contain zero.
If these were 95% confidence intervals and if we were using them to do frequentist hypothesis testing, the intervals containing zero would force us into one of the two possible outcomes: in this case, we could not reject the null. Having reached that binary decision, we’d emerge from the experiment not having learned much about any possible association of sentence acceptance with condition, or with the interaction between condition and sentence type.
But Bayesian models afford us much more interpretability. A 95% CrI containing zero doesn’t automatically nix the whole story. It just means that the model thinks that both negative and positive values are plausible values that the parameter in question could take on. And if it allocates more probability mass to the positive or the negative side of zero, that’s something we can report.
To their credit, some frequentist modellers also focus on effect size estimation and are moving away from hypothesis testing. But I’d argue that the Bayesian framework gives a nicely natural way of approaching this: in terms of allocation of belief to different parameter values.
The New Statistics
I’m not the only one who thinks this way: here are a couple voices from the literature advocating the New Statistics, an approach that shifts the focus from hypothesis testing to effect size estimation.
Kruschke, J. K., & Liddell, T. M. (2018). The Bayesian New Statistics: Hypothesis testing, estimation, meta-analysis, and power analysis from a Bayesian perspective. Psychonomic Bulletin & Review, 25(1), 178–206. https://doi.org/10.3758/s13423-016-1221-4
To report the results of this model
In tables
Use the fixef() function to extract only the posterior summaries of the fixed effects. And then use xtable() from the library xtable to generate a LaTeX version of this table, ready (with a bit of tidying) for your next paper.
In the bayesplot package, you can find plots of all kinds designed for Bayesian models. mcmc_trace() and mcmc_dens() were two of them, and mcmc_areas() is another:
This plot nicely visualises the posterior distributions in relation to one another, and I’ve customised it to show the mean as a vertical line, and the 95% CrI as the shaded region. It can be customised this way because all bayesplot plots are ggplot objects.
In prose
Finally, if you were going to write about this model in your paper, here’s how you might report it. For the sake of illustration, this example goes through every parameter—in reality, you’d probably focus mainly on the ones that are most relevant to your hypothesis (here, the interaction between condition and sentence type).
We fit a Bayesian linear model with a Bernoulli likelihood, predicting sentence acceptance as a function of condition, sentence type, and their interaction. The model used weakly regularising priors that we selected based on prior predictive checks.
The model estimates a likely-negative effect of condition (\(\beta\) = –0.18 log-odds, 95% CrI [–0.41, 0.04]), meaning that participants in the production condition are probably less likely to accept sentences than are participants in the comprehension condition. However, the 95% CrI contains positive values as well, indicating some uncertainty about the direction of the effect.
There is more certainty in the estimate of the much larger effect of sentence type (\(\beta\) = 1.84 log-odds, 95% CrI [–1.62, 2.08]); the model is sure that word order sentences are much more likely to be accepted than case-marking sentences are.
Finally, we hypothesised that we would observe a negative interaction, with a larger difference between sentence types in the comprehension condition than the production condition. However, the coefficient that the model estimates is almost entirely positive (\(\beta\) = 0.22, 95% CrI: [–0.01, 0.45]), giving much more credibility to an interaction going in the opposite direction to the one we predicted.
Notice that nowhere are we talking about “evidence” or “significance” or “rejecting the null”. We’re also not focused on whether or not the 95% CrIs contain zero. Rather, we’re looking at the range of estimates that the 95% CrIs contain, and observing the extent to which this is consistent with our hypotheses.
(If you do want to do Bayesian hypothesis testing and actually find “evidence” for one model over another, you can do this using Bayes factors.)
Take-home message about interpreting Bayesian models
The most that this Bayesian inferential model can do is allocate its belief over a range of possible effects, of possible parameter values; we are not finding evidence for or against any effects or hypotheses.
This is a crucial thing to know and understand, and it might feel uncomfortable and nebulous at first. But the payoff to dealing with this uncertainty is a model that is interpretable in more diverse, interesting ways, since you’re not limited to the binary decision of “reject the null” or “fail to reject the null”.