Bayesian models can be thought of as models of the generative process that produced the data.
In a way, what we’ve been doing so far is playing the model “backward”: we’re using observed data to try to figure out plausible values of the parameters inside the model.
But we can also play the model “forward”, and use the parameter values inside the model to generate data that the model thinks is plausible.
We’ll see tomorrow why this can be a useful thing to do!
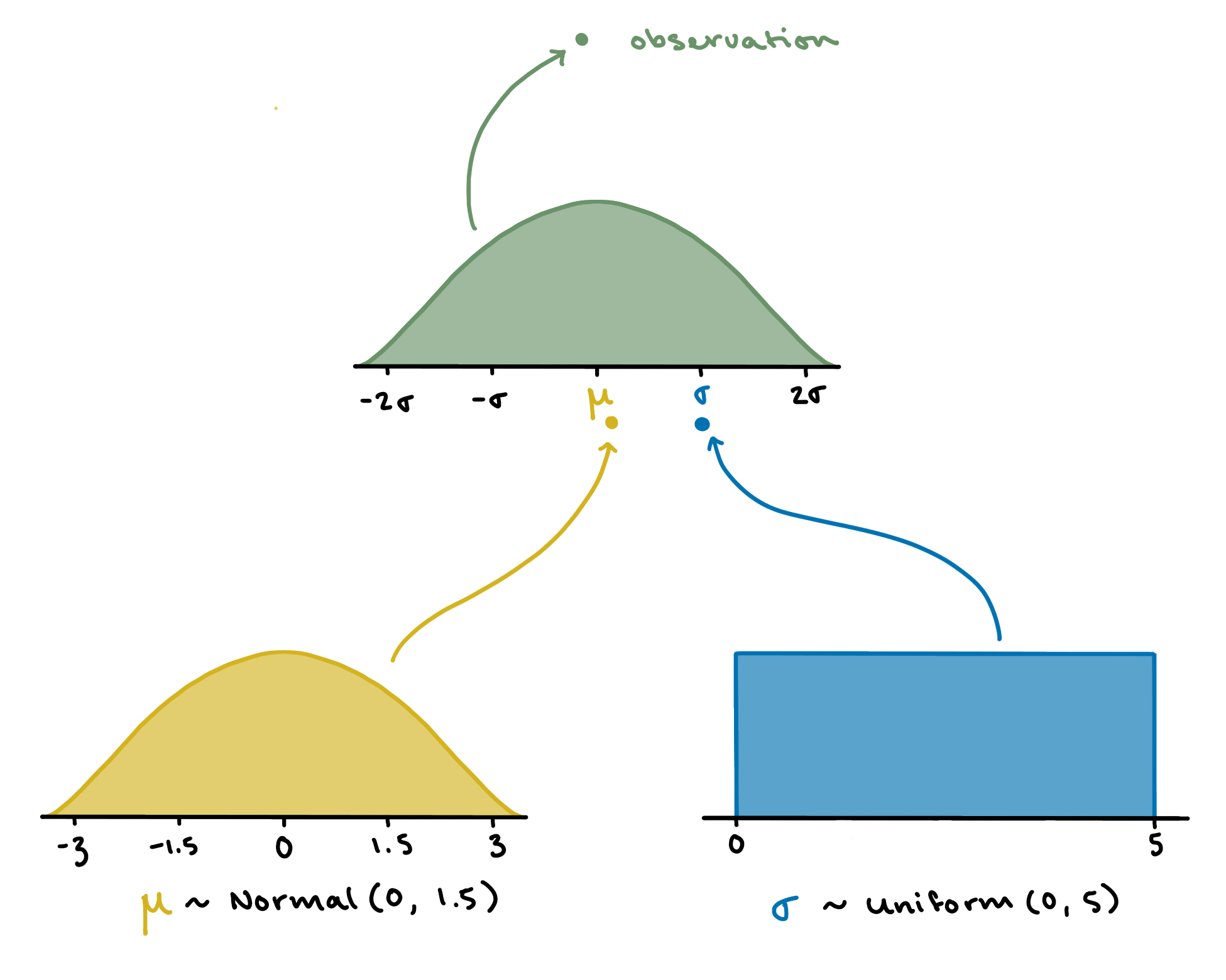
The following procedure will let us use this model to generate one data point.
To generate data from the likelihood \(Normal(\mu, \sigma)\), we need to define the currently-unknown parameters \(\mu\) and \(\sigma\).
For \(\mu\), sample one value \(a\) from \(Normal(0, 1.5)\).
For \(\sigma\), sample one value \(b\) from \(Uniform(0, 5)\).
Combine them to define the likelihood as \(Normal(a, b)\).
Sample one value from this distribution: this is one observation.
And to generate a whole dataset of size \(n\), we would just repeat this procedure \(n\) times. The distribution of data resulting from this procedure is sometimes called a “predictive distribution”.
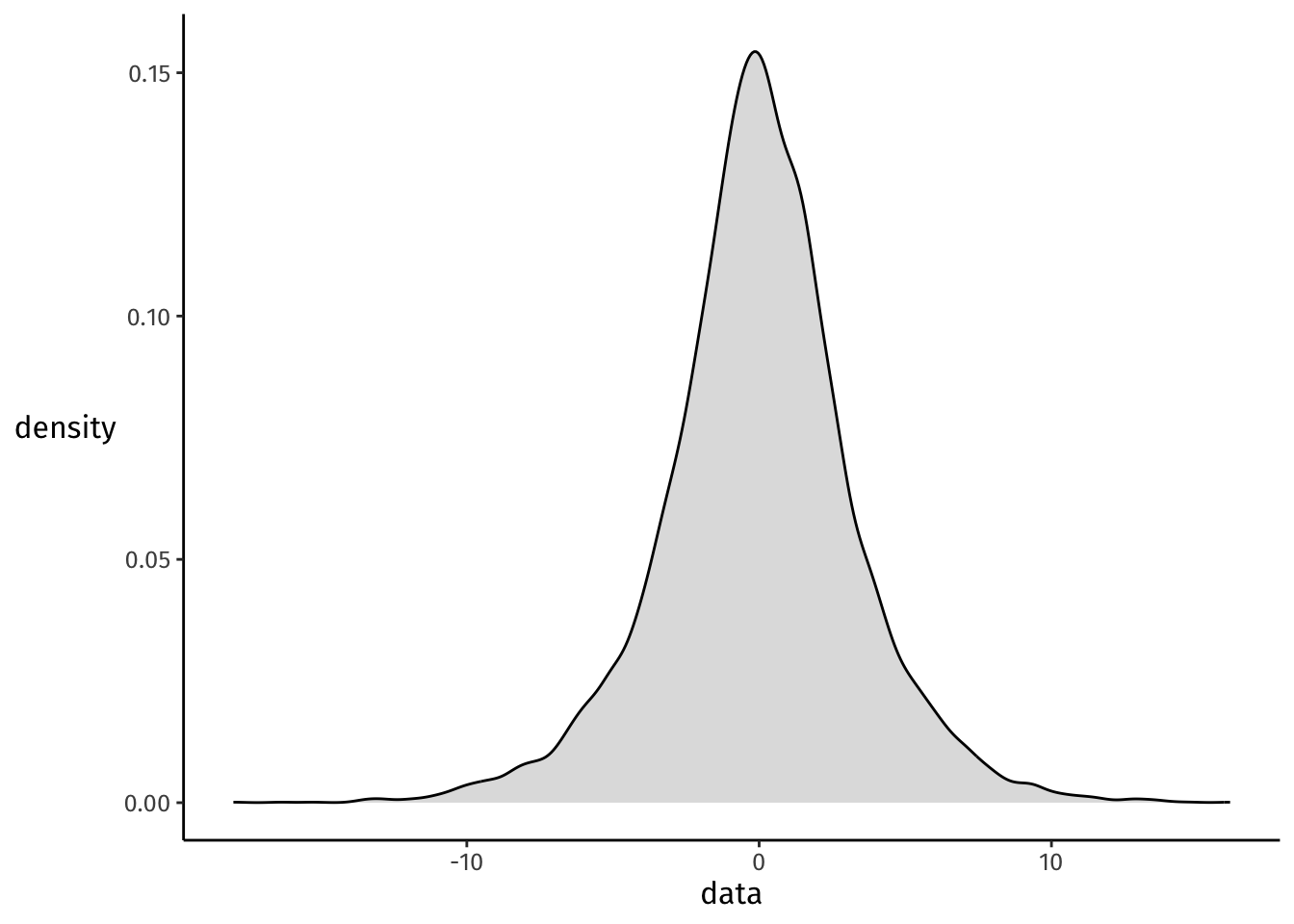
Here’s some R code that implements this procedure and plots the resulting predictive distribution.
# Set seed for reproducibility.set.seed(1)# Set the number of iterations.n <-10000# Define an accumulator list that will contain # each iteration's data point.accum <-c()# Let's gooooooofor(i in1:n){ a <-rnorm(1, mean =0, sd =1.5) b <-runif(1, min =0, max =5) data <-rnorm(1, mean = a, sd = b) accum <-c(accum, data)## Comment in to print out each iteration's likelihood## (best make n smaller first!)# print(paste0('Sampled ', round(data, 2), ' from Normal(', round(a, 2), ', ', round(b, 2), ')'))}# Make a density plot.tibble(data = accum) %>%ggplot(aes(x = data)) +geom_density(fill ='grey', alpha = .5)
considers data in the range of about [–10, 10] to be plausible outcomes.
Whether or not we agree will depend on the data and our real-world knowledge about it!
Tomorrow we’ll see how generating predictive distributions fits into the Bayesian modelling workflow.
Try it yourself!
The example here was for a model with a Normal likelihood that contains two parameters, one for the mean and the other for the standard deviation.
Can you adapt this code for one or both of the Bernoulli models we’ve been using for the lexical decision data?
The procedure will be similar:
Sample a value \(t\) from the prior for theta.
rbeta(1, x, y) for \(Beta(x, y)\) will be your friend here.
Use \(t\) to define a Bernoulli likelihood, and from that, sample one simulated observation.
rbinom(1, 1, t) will produce a 1 with probability \(t\) and a 0 with probability \(1-t\).
Binary data like this results in funny bimodal density plots, but still, give it a shot.
And if you feel daring, you could simulate many datasets, get the mean amount of sentences accepted in each (i.e., the proportion of responses = 1), and plot a histogram of the means of all those individual predictive distributions. That’s the kind of plot we’ll be looking at tomorrow.