Interpreting posteriors
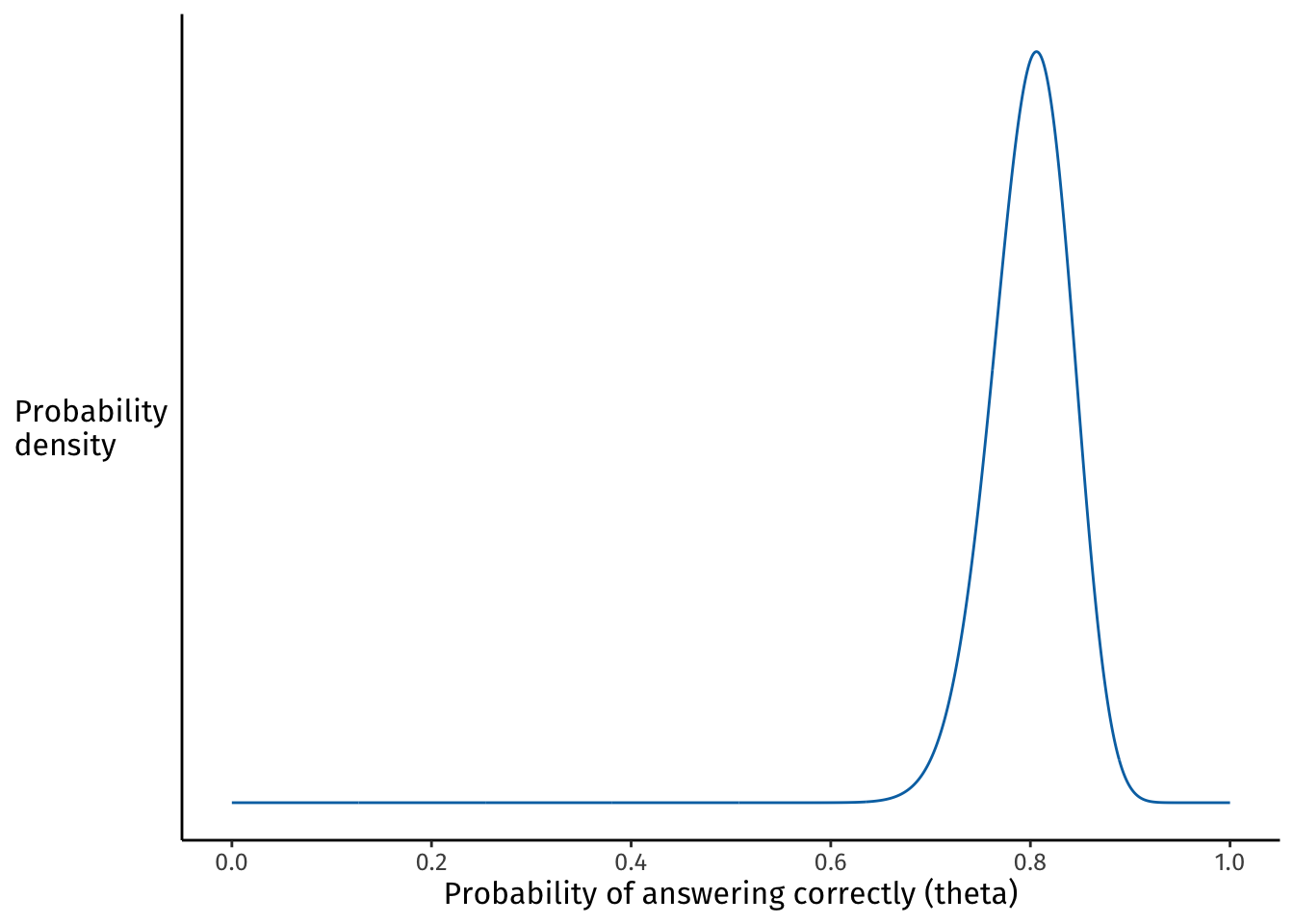
Here’s how the posterior distribution of the uniform-prior model looks after observing 80 successes out of 100 trials:
The x axis shows every possible probability for answering the lexical decision task correctly. The model allocates its belief over these probabilities based on the data we observed and the prior beliefs we encoded.
The posterior probability distribution therefore shows the model’s belief about how likely different probabilities are to be the true probability that generated the data.
Here, the model considers probabilities of success between about 0.7 and 0.9 to be the most plausible, given the observed data and our uniform prior beliefs.
We usually report posterior distributions by summarising their central tendency and dispersion.
- Central tendency: mean or median (depending on how skewed the distribution is).
- Dispersion: conventionally, the 95% Credible Interval.